Appendix - Land Use Land Cover Change
library(drift)
library(sf)
library(terra)
library(tmap)
library(maptiles)
library(ggplot2)
library(dplyr)
library(tidyr)
sf::sf_use_s2(FALSE)
# Agriculture superclass (10 m IO LULC can't reliably separate these phases)
ag_classes <- c("Crops", "Rangeland", "Bare Ground")
lulc_dir <- here::here("data", "lulc")
# Pre-computed by scripts/lulc_classify.R
lulc_all <- readRDS(file.path(lulc_dir, "lulc_summary.rds"))
# Spatial inputs
subbasins <- sf::st_read(
file.path(lulc_dir, "subbasins.gpkg"), quiet = TRUE
) |> sf::st_transform(4326)
fp_file <- file.path(lulc_dir, "floodplain.gpkg")
floodplain <- sf::st_read(fp_file, layer = "co_ff04", quiet = TRUE) |> sf::st_transform(4326)
# name_basin comes from break_points.csv via fresh::frs_watershed_split5.1 Modelled Floodplain
Land cover change is assessed within the modelled floodplain — the area delineated by the Valley Confinement Algorithm [VCA; Nagel et al. (2014), flooded package] for coho-accessible streams of 3rd order and greater, with lakes and wetlands included. The VCA uses a bankfull depth regression (Hall et al. 2007) scaled by flood_factor = 4 to approximate the functional floodplain — the area regularly influenced by high flows that sustains riparian vegetation, off-channel habitat, and large wood recruitment processes critical to salmon. The flood factor of 4 was selected as a conservative estimate between the empirically validated historical floodplain extent [flood factor = 3 on 10 m DEM; Hall et al. (2007)] and the recommended range of 5-7 for valley bottom delineation (Nagel et al. 2014), accounting for the coarser vertical resolution of the 30 m DEM used here (the national MRDEM-30). The modelled floodplain covers 171 km² along the Neexdzii Kwa (Bulkley River) and tributaries. All percentages and areas reported below refer to land cover within this modelled floodplain, not the full watershed.
IO Land Use Land Cover (10 m, Sentinel-2) is classified for 2017, 2020, and 2023 using the drift pipeline; each sub-basin’s modelled floodplain is analyzed independently.
# Use scenario-specific raster dir, fall back to legacy
fp_dir <- here::here("data", "lulc", "rasters", "co_ff04")
if (!dir.exists(fp_dir)) fp_dir <- here::here("data", "lulc", "rasters", "floodplain")
# Load classified rasters as named list
classified <- list(
"2017" = terra::rast(file.path(fp_dir, "classified_2017.tif")),
"2020" = terra::rast(file.path(fp_dir, "classified_2020.tif")),
"2023" = terra::rast(file.path(fp_dir, "classified_2023.tif"))
)
# Load transition raster (bidirectional, sieved at >= 1.0 ha patches).
# Filter the display summary to Trees -> agriculture transitions only —
# this keeps the layer toggles focused on tree-cover loss to agriculture.
trans_rast <- terra::rast(file.path(fp_dir, "transition.tif"))
trans_cats <- terra::cats(trans_rast)[[1]]
parts <- strsplit(trans_cats$transition, " -> ", fixed = TRUE)
trans_summary <- tibble::tibble(
id = trans_cats$id,
transition = trans_cats$transition,
from_class = vapply(parts, `[`, character(1), 1),
to_class = vapply(parts, `[`, character(1), 2)
) |>
dplyr::filter(from_class == "Trees", to_class %in% ag_classes)
transition <- list(raster = trans_rast, summary = trans_summary)
# Build interactive map with drift
m <- drift::dft_map_interactive(
classified,
aoi = floodplain,
transition = transition,
source = "io-lulc"
)
# Transition groups for layer control
trans_groups <- trans_summary$transition
# High-contrast sub-basin palette for interactive map (Brewer Set3, 9 classes)
sb_pal <- RColorBrewer::brewer.pal(9, "Set3")
# Zoom to floodplain extent on load
bb <- sf::st_bbox(sf::st_transform(floodplain, 4326))
m <- m |>
leaflet::fitBounds(bb[["xmin"]], bb[["ymin"]], bb[["xmax"]], bb[["ymax"]]) |>
leaflet::addPolygons(
data = subbasins,
fillColor = sb_pal[seq_len(nrow(subbasins))],
fillOpacity = 0.3,
color = "#333333",
weight = 2, opacity = 0.8, group = "Sub-basins",
label = ~name_basin
) |>
leaflet::addLegend(
position = "bottomleft",
colors = sb_pal[seq_len(nrow(subbasins))],
labels = subbasins$name_basin,
title = "Sub-basin",
opacity = 0.8,
group = "Sub-basins"
) |>
leaflet::addProviderTiles("OpenTopoMap", group = "OpenTopoMap") |>
leaflet::addLayersControl(
baseGroups = c("Light", "Esri Satellite", "Google Satellite", "OpenTopoMap"),
overlayGroups = c(names(classified), trans_groups, "AOI", "Sub-basins"),
options = leaflet::layersControlOptions(collapsed = FALSE)
) |>
leaflet::hideGroup(setdiff(names(classified), names(classified)[1]))
mFigure 5.196: Land cover classification within the modelled floodplain (IO LULC 10 m). Use radio buttons to toggle between 2017, 2020, and 2023 classified layers. Transition overlays show where Trees converted to other classes between 2017 and 2023. Sub-basin boundaries are shown as a toggleable overlay.
cache <- here::here("data", "spatial")
streams_all <- readRDS(file.path(cache, "streams.rds"))
lakes <- readRDS(file.path(cache, "lakes.rds"))
roads <- readRDS(file.path(cache, "roads.rds"))
railway <- readRDS(file.path(cache, "railway.rds"))
towns <- sf::st_sf(
name = c("Houston", "Smithers", "Burns Lake", "Topley"),
geometry = sf::st_sfc(
sf::st_point(c(-126.648, 54.398)),
sf::st_point(c(-127.176, 54.779)),
sf::st_point(c(-125.764, 54.230)),
sf::st_point(c(-126.246, 54.566)),
crs = 4326
)
)
# Dissolved roads by route
roads_dissolved <- roads |>
dplyr::filter(!is.na(route)) |>
dplyr::group_by(route) |>
dplyr::summarise(geom = sf::st_union(geom), .groups = "drop")
# Bounding box from sub-basins with padding tuned for 8.5x11
bbox <- sf::st_bbox(subbasins)
bbox["ymax"] <- bbox["ymax"] + 0.06
bbox["ymin"] <- bbox["ymin"] - 0.06
bbox["xmin"] <- bbox["xmin"] - 0.04
bbox["xmax"] <- bbox["xmax"] + 0.04
# Clip streams and lakes to bbox
bbox_clip_sf <- sf::st_as_sfc(bbox) |> sf::st_set_crs(4326)
streams_clip <- streams_all |> sf::st_make_valid() |> sf::st_crop(bbox_clip_sf)
lakes_clip <- lakes |> sf::st_make_valid() |> sf::st_crop(bbox_clip_sf)
# Stream labels (5th order+ named)
stream_label_pts <- streams_clip |>
dplyr::filter(!is.na(gnis_name) & stream_order >= 5) |>
dplyr::group_by(gnis_name) |>
dplyr::summarise(geom = sf::st_union(geom), .groups = "drop") |>
dplyr::mutate(geometry = sf::st_point_on_surface(geom)) |>
sf::st_set_geometry("geometry") |>
sf::st_set_crs(4326)
# Lake labels (>1 km²)
lake_labels <- lakes_clip[!is.na(lakes_clip$name) & lakes_clip$area_km2 > 1, ]
# Hillshade basemap
bbox_sf <- sf::st_as_sfc(bbox) |> sf::st_set_crs(4326)
relief <- maptiles::get_tiles(bbox_sf, provider = "Esri.WorldShadedRelief",
zoom = 10, crop = TRUE)
basemap_stars <- stars::st_as_stars(relief)
# Earthy sub-basin palette (9 sub-basins)
earth_pal <- c("#A67C52", "#C4A882", "#8B9E6B", "#D4A76A",
"#7A8B6E", "#BFA07A", "#9B8E6E", "#C2B280", "#8FA87C")
tmap::tmap_mode("plot")
tmap::tm_shape(basemap_stars, bbox = bbox) +
tmap::tm_rgb() +
# Sub-basins
tmap::tm_shape(subbasins) +
tmap::tm_polygons(
fill = "name_basin",
fill.scale = tmap::tm_scale_categorical(values = earth_pal),
fill_alpha = 0.35,
col = "#5C4033", lwd = 1.5,
fill.legend = tmap::tm_legend(show = FALSE)
) +
tmap::tm_text("name_basin", size = 0.65, col = "#3B2716", fontface = "bold",
options = tmap::opt_tm_text(shadow = TRUE)) +
# Floodplain
tmap::tm_shape(floodplain) +
tmap::tm_polygons(fill = "#2d6a2e", fill_alpha = 0.30,
col = "#2d6a2e", lwd = 0.8) +
# Lakes
tmap::tm_shape(lakes_clip) +
tmap::tm_polygons(fill = "#c6ddf0", col = "#7ba7cc", lwd = 0.4, fill_alpha = 0.85) +
tmap::tm_shape(lake_labels) +
tmap::tm_text("name", size = 0.55, col = "#1a5276", fontface = "italic") +
# Streams
tmap::tm_shape(streams_clip |> dplyr::filter(stream_order >= 4)) +
tmap::tm_lines(col = "#7ba7cc", lwd = 0.4) +
tmap::tm_shape(streams_clip |> dplyr::filter(stream_order >= 5)) +
tmap::tm_lines(col = "#7ba7cc", lwd = 0.8) +
tmap::tm_shape(stream_label_pts) +
tmap::tm_text("gnis_name", size = 0.60, col = "#1a5276", fontface = "italic") +
# Railway
tmap::tm_shape(railway) +
tmap::tm_lines(col = "black", lwd = 1.2) +
tmap::tm_shape(railway) +
tmap::tm_lines(col = "white", lwd = 0.6, lty = "42") +
# Roads
tmap::tm_shape(roads_dissolved |> dplyr::filter(route == "16")) +
tmap::tm_lines(col = "#c0392b", lwd = 2.0) +
tmap::tm_shape(roads_dissolved |> dplyr::filter(route != "16")) +
tmap::tm_lines(col = "#e67e22", lwd = 1.2) +
# Towns
tmap::tm_shape(towns) +
tmap::tm_dots(fill = "black", size = 0.30) +
tmap::tm_text("name", size = 0.65, xmod = 0.8, ymod = -0.6,
col = "grey10", fontface = "bold") +
# Scale bar
tmap::tm_scalebar(breaks = c(0, 10, 20),
position = c("left", "bottom"),
text.size = 0.6) +
# Legend
tmap::tm_add_legend(
type = "polygons",
labels = "Modelled floodplain",
fill = "#2d6a2e",
col = "#2d6a2e",
lwd = 1
) +
tmap::tm_add_legend(
type = "lines",
labels = c("Highway 16", "Secondary highway", "Railway (CN)"),
col = c("#c0392b", "#e67e22", "black"),
lwd = c(2, 1.2, 1.2)
) +
tmap::tm_layout(
frame = TRUE,
inner.margins = c(0.005, 0.005, 0.005, 0.005),
outer.margins = c(0.002, 0.002, 0.002, 0.002),
legend.position = c("right", "top"),
legend.frame = TRUE,
legend.bg.color = "white",
legend.bg.alpha = 0.85
)5.2 Agriculture Definition
For this analysis, “Agriculture” groups three IO LULC classes that can represent different phases of the same land use at 10 m resolution: Rangeland (fallow, grazed pasture), Crops (actively growing), and Bare Ground (tilled or harvested). A single field can be classified differently depending on the satellite overpass date relative to the growing season.
lulc_all |>
filter(class_name %in% ag_classes) |>
mutate(year = factor(year),
class_name = factor(class_name, levels = c("Bare Ground", "Crops", "Rangeland"))) |>
ggplot(aes(x = year, y = pct, fill = class_name)) +
geom_col() +
facet_wrap(~name_basin, nrow = 3) +
scale_fill_manual(
values = c("Rangeland" = "#FFBB22", "Crops" = "#E49635", "Bare Ground" = "#A59B8F"),
name = NULL
) +
theme_minimal() +
labs(
y = "% of Modelled Floodplain",
x = NULL
)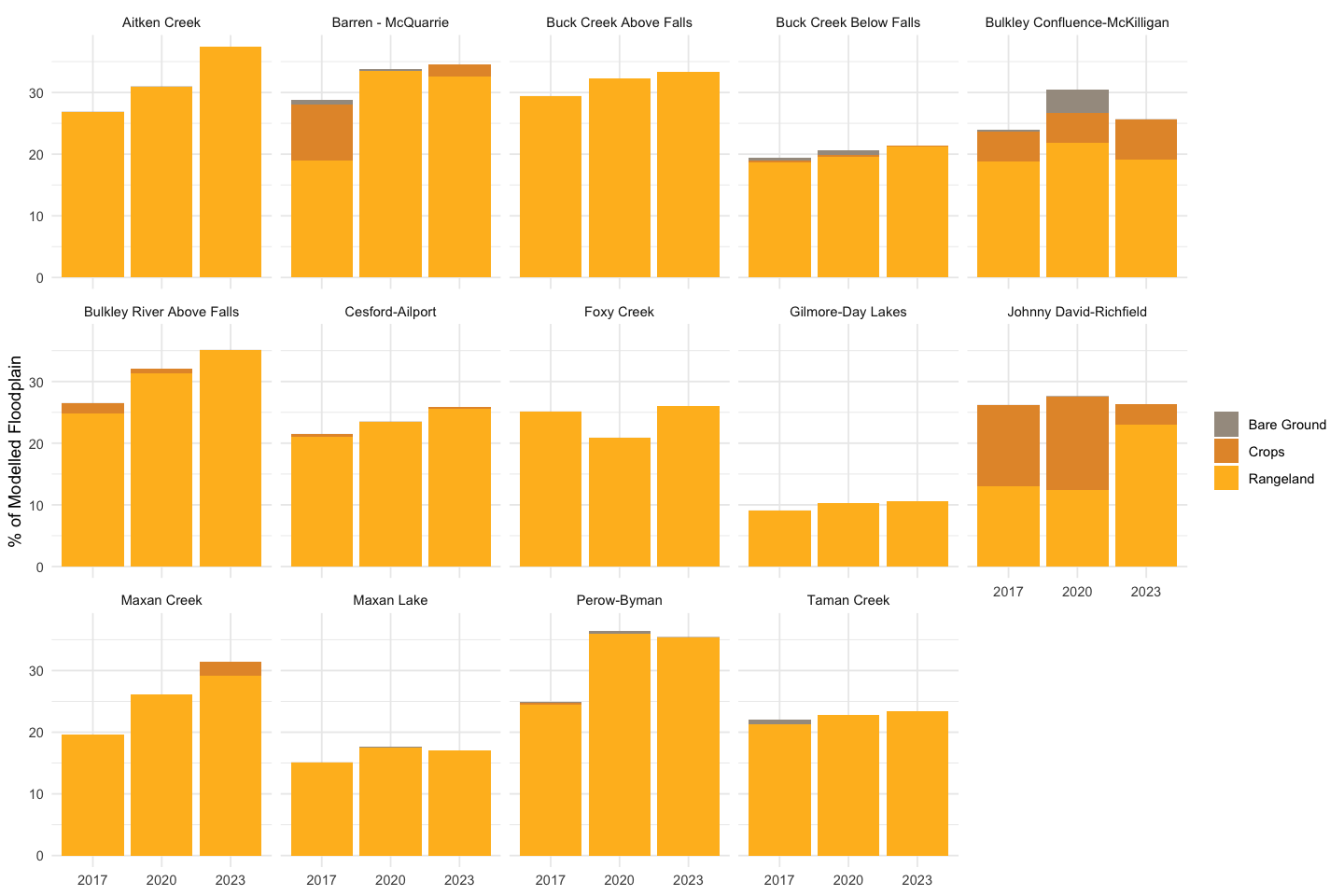
Figure 5.197: Composition of the Agriculture superclass within each sub-basin’s modelled floodplain. Rangeland dominates; Crops and Bare Ground are minor components.
5.3 Sub-Basin Ranking
Tree loss and agriculture gain do not sum to zero because other IO LULC classes (Built Area, Water, Flooded Vegetation) also gain or lose area between years. The other_ha column captures this residual — positive values indicate net area flowing into non-tree, non-agriculture classes (e.g., Built Area expansion, water level changes, channel migration). Values below derive from the sieved transition vector (change patches ≥1 ha, see Methods) so they match the headline figures reported in Results.
# Sub-basin ranking derives from the sieved transition vector (patches >= 1.0 ha)
# so this table -- and the ranking chart below, which reads from summary_tab --
# match the headline tree-loss figures in Results and the executive summary.
trans_v_app <- sf::st_read(
file.path(lulc_dir, "floodplain_landcover.gpkg"),
layer = "transition_co_ff04_2017_2023", quiet = TRUE
) |> sf::st_drop_geometry()
fp_areas <- lulc_all |>
filter(year == 2017) |>
group_by(name_basin) |>
summarize(fp_ha = round(sum(area), 1), .groups = "drop")
sieved_delta_app <- trans_v_app |>
group_by(name_basin) |>
summarize(
tree_loss_ha = sum(area_ha[to_class == "Trees"]) -
sum(area_ha[from_class == "Trees"]),
ag_gain_ha = sum(area_ha[to_class %in% ag_classes]) -
sum(area_ha[from_class %in% ag_classes]),
.groups = "drop"
)
summary_tab <- sieved_delta_app |>
left_join(fp_areas, by = "name_basin") |>
mutate(
tree_loss_pct = round(tree_loss_ha / fp_ha * 100, 1),
ag_gain_pct = round(ag_gain_ha / fp_ha * 100, 1),
tree_loss_ha = round(tree_loss_ha, 1),
ag_gain_ha = round(ag_gain_ha, 1),
other_ha = round(-tree_loss_ha - ag_gain_ha, 1)
) |>
select(name_basin, fp_ha, tree_loss_pct, tree_loss_ha,
ag_gain_pct, ag_gain_ha, other_ha) |>
arrange(tree_loss_ha)my_caption <- "Tree cover loss and agriculture gain within modelled floodplain by sub-basin (2017-2023), from transition patches >= 1 ha. Negative values = loss. Agriculture = Crops + Rangeland + Bare Ground. other_ha = residual area change attributed to remaining classes (Built Area, Water, Flooded Vegetation, etc.)."
my_tab_caption()knitr::kable(summary_tab, digits = 1,
caption = "Tree cover loss and agriculture gain within modelled floodplain by sub-basin (2017-2023), from transition patches >= 1 ha. other_ha = residual attributed to remaining classes.")ranking_ha <- summary_tab |>
select(name_basin, Trees = tree_loss_ha, Agriculture = ag_gain_ha) |>
arrange(Trees)
ranking_ha |>
pivot_longer(cols = c(Trees, Agriculture), names_to = "class", values_to = "delta") |>
mutate(name_basin = factor(name_basin, levels = ranking_ha$name_basin)) |>
ggplot(aes(x = name_basin, y = delta, fill = class)) +
geom_col(position = "dodge") +
scale_fill_manual(values = c("Trees" = "#006400", "Agriculture" = "#c0392b"), name = NULL) +
geom_hline(yintercept = 0, linewidth = 0.5) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
labs(
y = "Change in Area (ha, 2017-2023)",
x = NULL
)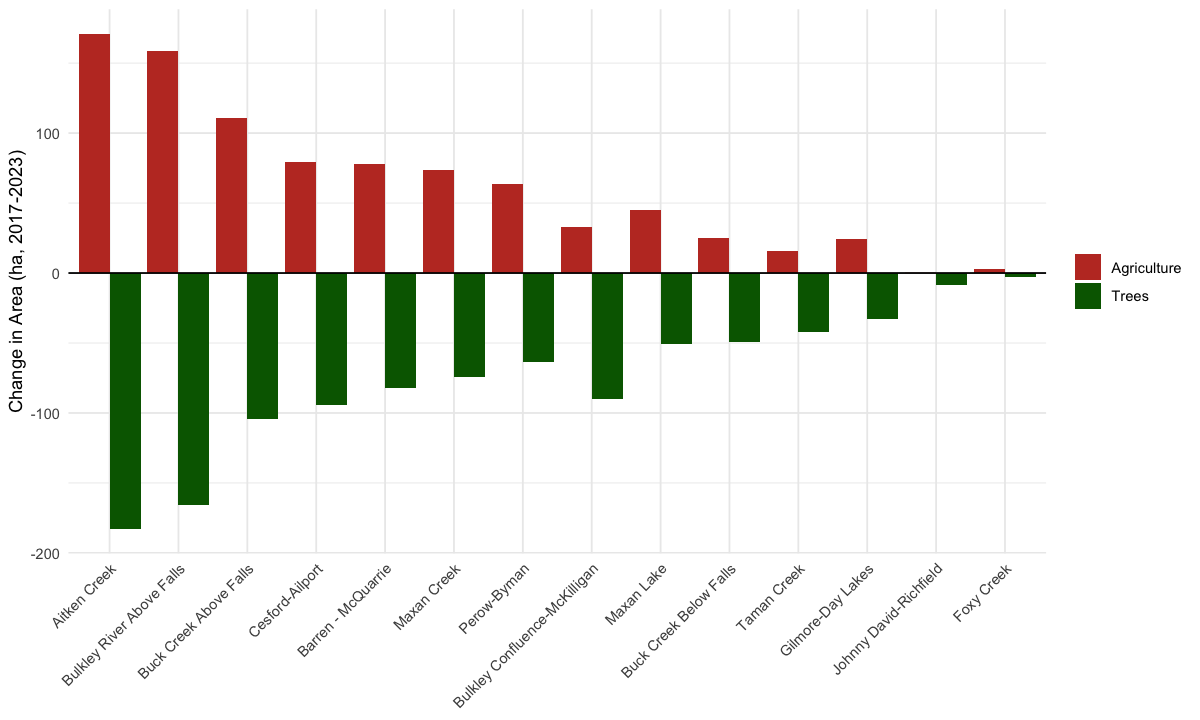
Figure 5.198: Change in tree cover and agriculture area (ha) within modelled floodplain by sub-basin, 2017-2023, from transition patches >= 1 ha. Agriculture = Crops + Rangeland + Bare Ground.
5.4 Land Cover Composition
The full land cover composition by class, sub-basin, and year is given below.
wide <- lulc_all |>
left_join(fp_areas, by = "name_basin") |>
select(name_basin, fp_ha, year, class_name, pct) |>
pivot_wider(names_from = year, values_from = pct) |>
arrange(name_basin, class_name)my_caption <- "Land cover composition (% of modelled floodplain) by sub-basin and year. fp_ha = total modelled floodplain area."
my_tab_caption()